The data that unlocked scaling LLMs doesn’t exist for biology. Functional datasets in Bio are too small, too noisy,
and weren’t built for training large models. Instance has built the platform to change that: end-to-end generation of
scalable, training-optimized functional datasets across binding, expression, and variant-effect modalities.
You provide the input, thousands to millions of candidate sequences, and what functions you want labeled. Instance gives
you back the annotated dataset including rich metadata from the wet-lab experimental validation. Training on biological
data finally fits the shape and scale of every other type of data you train on.
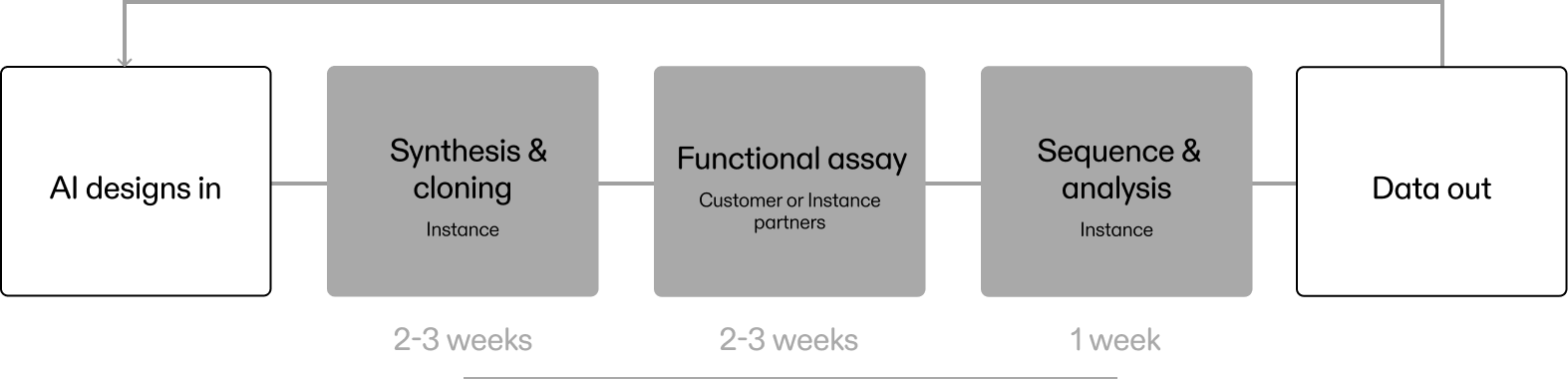
You can choose to run the assay yourself and send us samples or alternatively we can run the assay for you through our
partners.